All the Ways You Can Model Your Data (And When to Use Each)
If you don’t feel like listening right, you can listen to audio summary generated by NotebookLM.
Introduction
Many organizations struggle to use their data effectively, not because they lack data, but because they lack a clear understanding of how to structure it. This is why data modeling has become so critical. As more companies recognize the need to organize their data thoughtfully, the demand for this skill has grown.
However, learning about it can be a challenge. When I was researching this topic, I found myself jumping between scattered articles, YouTube videos, and book chapters. My goal here is to create the comprehensive guide I wish I’d had—a single resource for aspiring data professionals to grasp the fundamentals.
In this article, we will explore different data modeling techniques, explain when to use each one, and see what they look like in the real world.
Part I: The Data Modeling Process: From Whiteboard to Database
You can think of data modeling as creating a blueprint for how data is stored and structured, ensuring it can be used effectively. The end users of these blueprints are varied:
- BI Developers, who build dashboards to answer, “How many goods did we sell last quarter?”
- ML Engineers, who need data to predict, “Which users are likely to churn?”
- Data Analysts, who seek insights like, “What do users who abandon their cart have in common?”
As a data specialist, you are a sculptor. You receive the raw “data clay” and must shape it into different forms. But before you start sculpting, you need a plan. This planning process is typically broken down into three distinct phases, moving from high-level ideas to a concrete implementation.
Phase 1: The Conceptual Model – The Whiteboard Sketch
This is the “what” phase. The goal is to understand the business, not the technology.
-
The Action: As an analytics engineer, your first step is to talk to business stakeholders—product managers, sales leads, operations managers. You ask questions like: “What are the most important objects in your world?” and “How do they interact?”
-
The Artifact: The output is a high-level Entity-Relationship Diagram (ERD). This is often a simple drawing on a whiteboard or in a tool like Lucidchart or Miro. It focuses only on the main entities and their relationships.
-
The Example: For our online shop, the conceptual ERD would be simple:
[Customer]— (places) —>[Order]— (contains) —>[Product] -
The Result: You have a shared understanding with the business, completely free of technical jargon.
If you need a refresher on creating ER diagrams, feel free to watch this video.
Phase 2: The Logical Model – The Blueprint
This is the “how” phase. Here, you enrich the conceptual model with technical detail, but still without committing to a specific database technology.
-
The Action: Now you talk to the downstream users (BI Devs, Data Scientists) and source system experts. You ask: “What specific attributes do you need for your analysis?” and “Where does this data come from?”
-
The Artifact: The ERD evolves into a detailed Logical Model. You add attributes to each entity and define primary keys (PK) and foreign keys (FK) to formalize the relationships.
-
The Example: The logical model for our online shop would look more detailed:
Customer(
customer_id(PK),first_name,email)Order(
order_id(PK),customer_id(FK),order_date) -
The Result: You have a detailed, technology-agnostic blueprint that specifies all the columns, keys, and relationships needed to answer the business questions.
Phase 3: The Physical Model – The Implementation
This is the “build” phase. You translate the logical blueprint into a real database structure.
- The Action: This is where you, the data professional, make critical design decisions. Based on the use cases, you choose a specific modeling pattern. Will it be a normalized Relational Model for a transactional system? Or a denormalized Star Schema for a fast analytics warehouse?
- The Artifact: The final output is DDL (Data Definition Language) code—the
CREATE TABLEstatements for your chosen database (e.g., Snowflake, PostgreSQL, BigQuery). - The Result: A functional database structure, ready to be loaded with data.
We now have our process: from the conceptual sketch to the detailed blueprint. The final, critical step is choosing what to sculpt. The following sections will introduce you to the most common data modeling patterns—the different shapes you can give your data clay—and guide you on choosing the right one for the job.
Part II. Foundational Technique: The Relational Model
In Part I, we used Entity-Relationship Diagrams (ERDs) to create our conceptual and logical blueprints. Now, we must translate that blueprint into a physical database. The most direct and common way to do this is by using the relational model.
The relational model is the physical implementation of the concepts from the Entity-Relationship (ER) model. It takes our abstract entities and relationships and realizes them as concrete tables, columns, and keys. First proposed by Edgar F. Codd in 1970, it organizes data into tables (or “relations”) made of rows and columns. These tables are linked to one another using keys, allowing you to represent complex relationships between different business entities.
Because nearly every modern database is relational in some way, understanding this model is the first step to mastering all other techniques.
A Real-World Example
Let’s use our online shop example. A simple relational model for it might look like this:

Notice how the data is “normalized”—broken apart into distinct tables for each entity (customers, orders, payments). The user_id in the orders table links back to a specific customer, and the order_id in the payments table links back to a specific order.
This structure is optimized for writing and updating data with high integrity. For example, if a customer changes their name, you only have to update it in one place: the customers table. This is the typical structure for an application’s production database (often called an OLTP, or Online Transaction Processing, system).
When to Use a Relational Model
While relational structures are the backbone of most databases, this highly normalized form is best suited for specific scenarios.
Strengths (Especially for OLTP/Application Databases):
- Data Integrity: Minimizes data redundancy and prevents update anomalies.
- Flexibility: Can be queried in countless ways, as all entities are logically separated.
- Transactional Efficiency: Excellent for handling a high volume of reads, writes, and updates (e.g., placing an order, updating a user profile).
Challenges (When Used Directly for Analytics/BI):
-
Query Complexity: Answering business questions often requires joining many tables together, which can be complex to write and slow to execute. For example, to find total sales by customer name, you’d need to join
customers,orders, andpayments. -
Performance: As data volume grows, the cost of these joins becomes significant, making it a less-than-ideal choice for large-scale analytics where query speed is critical.
Querying the Relational Model: Strengths and Weaknesses
To see the trade-offs in practice, let’s look at two different types of queries against our relational model.
Example of a Strength: Transactional Lookup
This model excels at retrieving specific, related information for an application. For instance, fetching the order history for a single customer is fast and efficient because it uses indexed keys.
Use Case: A customer logs into their account on the e-commerce website and wants to see their past orders.
-- This query is fast because it joins on primary/foreign keys
-- and filters for a single user.
SELECT
o.id AS order_id,
o.status,
o.order_date,
p.amount,
p.payment_method
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN payments p ON o.id = p.order_id
WHERE u.email = '[email protected]'
ORDER BY o.order_date DESC;
This is a classic OLTP query. It’s targeted, handles a low volume of data per request, and is optimized for the application’s needs.
Example of a Weakness: Analytical Aggregation
The model’s weakness appears when you try to answer broad, analytical questions that require aggregating data across many entities.
Use Case: A business analyst wants to find the total sales amount for each customer to identify the top spenders.
-- This query requires multiple joins to answer a single business question.
-- As tables grow, the cost of these joins becomes significant.
SELECT
u.first_name,
u.last_name,
COUNT(DISTINCT o.id) AS number_of_orders,
SUM(p.amount) AS total_sales_amount
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN payments p ON o.id = p.order_id
GROUP BY
u.id, -- Best practice to group by the unique ID
u.first_name,
u.last_name
ORDER BY
total_sales_amount DESC
LIMIT 10;
This query is simple enough here, but it already requires three tables to be joined. To add product information, you would need another join. To add shipping information, another. This increasing complexity and performance degradation on large datasets is the primary reason we transform this model into a Star Schema for analytics.
Because of these challenges, we often transform this foundational relational model into other structures—like a dimensional model—for analytics. It serves as the perfect, clean source but not the final destination.
Part III. The Star Schema: A Model Built for Analytics
In the last section, we saw how a relational model organizes data cleanly by separating entities like users, orders, and payments. This structure is perfect for an application’s database because it prevents data duplication and makes updates efficient.
However, it has a major drawback for analytics. To answer a simple business question like, “What was our total sales amount by product type for users in California?” you would need to perform multiple complex JOIN operations across several tables. As your data grows, these queries become slow and cumbersome.
This is where dimensional modeling comes in.
Facts and Dimensions: The Verbs and Nouns of Your Business
Dimensional modeling is a technique designed specifically for analytics and business intelligence. It reframes our data by categorizing tables into two simple types:
- Facts: These tables record events or actions. They contain the numeric measurements and metrics you want to analyze—the “verbs” of your business. Examples include a payment being completed, an item being added to a cart, or a user logging in. Facts are typically narrow and very long (many rows).
- Dimensions: These tables provide the context for the facts. They contain the descriptive attributes about the people, products, places, and times involved—the “nouns” of your business. Examples include user information (
dim_users), product details (dim_products), and calendar dates (dim_dates). Dimensions are typically wide (many columns) and shorter.
The Star Schema: Implementing the Dimensional Model
The most common and effective way to implement a dimensional model is by using a star schema. It gets its name from its visual structure: a central fact table connected directly to multiple dimension tables, resembling a star.
Let’s remodel our e-commerce data into a star schema.
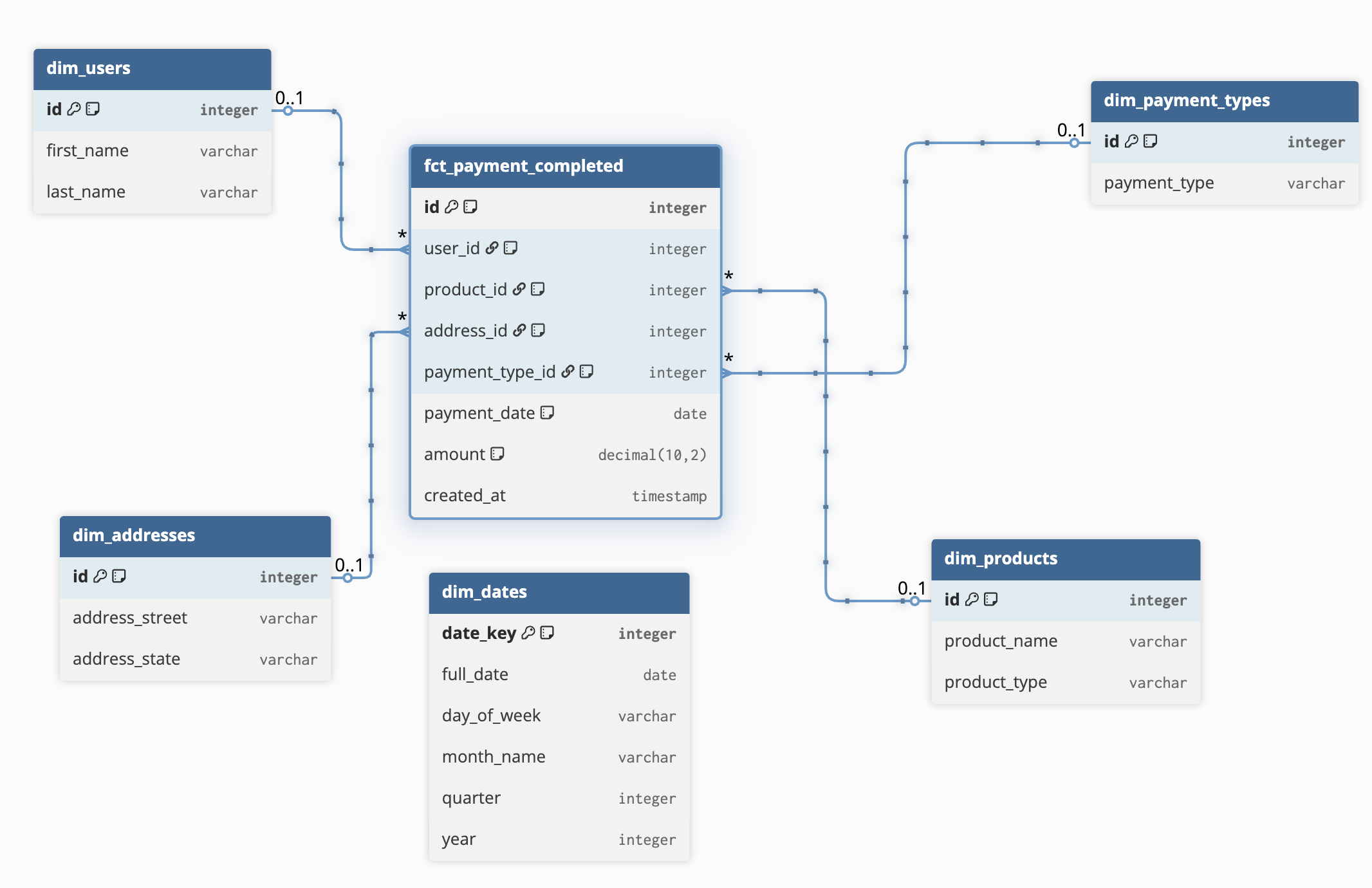
In this model:
fct_payment_completedis our Fact Table. It contains the core metric we want to measure (amount) and foreign keys to all the relevant dimensions.dim_users,dim_products,dim_addresses, anddim_datesare our Dimension Tables. They hold all the descriptive context.
Why is this better for analytics?
The beauty of the star schema lies in its simplicity and performance. Let’s compare how you would answer a business question.
Relational Model Query (Complex):
SELECT
c.first_name,
SUM(p.amount)
FROM users c
JOIN orders o ON c.id = o.user_id
JOIN payments p ON o.id = p.order_id
GROUP BY 1;
Requires three tables and two joins just to link a user to their payment amount.
Star Schema Query (Simple):
SELECT
u.first_name,
SUM(f.amount)
FROM fct_payment_completed f
JOIN dim_users u ON f.user_id = u.id
GROUP BY 1;
Requires only two tables and one simple join. It’s easier to write, easier to understand, and significantly faster to run on a data warehouse.
The star schema denormalizes the data on purpose. Information like a user’s name is repeated for every fact, but this trade-off is worth it because modern data warehouses are optimized for this structure, making analytical queries incredibly fast.
Good Fit For:
You should choose a star schema when:
- The primary goal is business intelligence and reporting. You need to slice, dice, and aggregate data quickly.
- You are building a centralized data warehouse in a system like Snowflake, BigQuery, or Redshift.
- You want a predictable and navigable structure that is intuitive for Data Analysts and BI Developers.
This is the sculptor choosing to make a wide, stable mug for the BI Developer—it’s perfectly shaped for its purpose of being easy to “drink” insights from.
Part IV. One Big Table (OBT): The Ultimate in Simplicity and Speed
In the last section, we saw how the Star Schema improves on the relational model for analytics by reducing the number of joins needed. But what if we could eliminate JOINs entirely?
This is the goal of the One Big Table (OBT) model. As the name implies, this approach involves creating a single, very wide, and completely denormalized table that contains all the facts and dimensional attributes needed for a specific area of analysis.
Think of it as taking a Star Schema and pre-joining everything. You take your central fact table and pull in all the useful columns from every dimension table it connects to, creating one massive, flat table.
From Star Schema to OBT
Let’s take our e-commerce Star Schema from the previous section. To create an OBT for analyzing payments, we would write a query that joins fct_payment_completed with all its dimensions.
The Logic (Conceptual SQL):
CREATE TABLE obt_payments AS
SELECT
-- Facts from the fact table
f.amount,
f.payment_date,
-- Attributes from dim_users
u.first_name,
u.last_name,
-- Attributes from dim_products
p.product_name,
p.product_type,
-- Attributes from dim_addresses
a.address_state,
a.address_street,
-- ... and so on for all other dimensions
FROM fct_payment_completed AS f
LEFT JOIN dim_users AS u ON f.user_id = u.id
LEFT JOIN dim_products AS p ON f.product_id = p.id
LEFT JOIN dim_addresses AS a ON f.address_id = a.id
-- ... other joins
;
The Resulting OBT Structure:
The final table, obt_payments, would have no foreign keys. All the information is present on every single row.
| amount | payment_date | first_name | last_name | product_name | product_type | address_state |
|---|---|---|---|---|---|---|
| 19.99 | 2023-10-25 | Jane | Doe | T-Shirt | Apparel | CA |
| 19.99 | 2023-10-25 | Jane | Doe | T-Shirt | Apparel | CA |
| 49.50 | 2023-11-01 | John | Smith | Coffee Maker | Kitchen | NY |
| … | … | … | … | … | … | … |
Notice the data redundancy. “Jane Doe” and her state “CA” are repeated for every payment event she has. In an OBT, this is not a bug; it’s a feature.
Why is this good?
The OBT model is built for two things: simplicity and performance.
Star Schema Query (Still requires a join):
SELECT
u.first_name,
SUM(f.amount)
FROM fct_payment_completed f
JOIN dim_users u ON f.user_id = u.id
GROUP BY 1;
OBT Query (No joins needed):
SELECT
first_name,
SUM(amount)
FROM obt_payments
GROUP BY 1;
By eliminating joins, queries become incredibly simple to write and lightning-fast to execute.
Good Fit For:
OBT is a derived model; it’s almost never the foundational layer of a data warehouse. It’s the sculptor taking their star-shaped mug and melting it down into a flat sheet, perfect for a specific purpose.
- Machine Learning (ML) Feature Engineering: Data scientists often need a single, flat table where each row is an observation and columns are features. OBT is the perfect format for training ML models.
- Powering High-Performance BI Dashboards: For a critical, company-wide dashboard that many users access, an OBT can ensure visuals load instantly, as the BI tool (like Tableau or Power BI) doesn’t have to compute any joins.
- Data Exploration (Ad-Hoc Analysis): It can provide a simple, intuitive playground for analysts who don’t want to worry about the underlying joins and just want to explore the data.
- Exporting Data: When sending data to a system that doesn’t understand relational structures.
Challenges and Limitations
- Data Redundancy & Cost: Storing the same information over and over can significantly increase storage costs.
- Maintenance: OBTs are not a source of truth. If a user’s name changes in
dim_users, the entireobt_paymentstable must be completely rebuilt. They are artifacts that must be refreshed from their source (like a star schema). - Inflexibility: An OBT is built for a specific purpose. If an analyst wants to ask a question that requires a piece of data not included in the OBT (e.g., “group sales by the user’s signup month”), the table is useless, and a new one must be created.
Part V. The Data Vault: A Model for Auditability and Scale
So far, we’ve discussed the relational model for transactional systems and the star schema for analytics. But what if your primary needs are historical accuracy and the flexibility to integrate dozens of changing source systems?
This is where the Data Vault model comes in. It’s an enterprise-level modeling methodology designed specifically for the data warehouse integration layer, prioritizing auditability and scalability above all else.
Full disclosure: Data Vault is a deep and nuanced subject. Implementing it correctly requires significant expertise, and this section serves as a high-level introduction rather than a complete guide. For those serious about mastering it, the foundational text is “Building a Scalable Data Warehouse with Data Vault 2.0” by its creator, Daniel Linstedt.
The Core Idea: Never Lose History
The central principle of Data Vault is its insert-only design. In a traditional model, if a student changes their major, you might run an UPDATE statement to overwrite the old value. In a Data Vault, you never overwrite. Instead, you insert a new row with the new major and a timestamp.
This creates an immutable, fully auditable record of every change that has ever occurred. You can rewind the clock and see exactly what your data looked like at any point in history.
The Building Blocks: Hubs, Links, and Satellites
To achieve this, Data Vault breaks entities down into three distinct table types, using a university system as our example:
- Hubs: These are the anchors of the model. They contain only the stable, unique business keys for a core entity.
h_student(business key:student_id)h_course(business key:course_code)
- Links: These tables establish the relationships between hubs. They contain only the keys of the hubs they connect.
l_enrollment(connectsh_studentandh_courseto show that a student registered for a course).
- Satellites: These tables contain all the descriptive attributes, and this is where the history is stored. A satellite attaches to a single hub or link.
sat_student_details(attached toh_student, storesfirst_name,last_name).sat_student_major(attached toh_student, storesmajor). If a student changes their major, a new row is added here.sat_enrollment_grade(attached tol_enrollment, stores thefinal_gradefor that specific enrollment).
Here’s how they fit together:
[sat_student_details] \
[sat_student_major] -- [h_student] -- [l_enrollment] -- [h_course] -- [sat_course_details]
|
[sat_enrollment_grade]
Where Does It Fit?
A Data Vault is almost never queried directly by business users. It is not intuitive for analytics. Instead, it serves as a robust, auditable integration layer in your data warehouse.
Think of it like the sculptor’s library of raw materials. The Data Vault is your perfectly organized, historically complete, and resilient collection of every type of “data clay.” From this stable foundation, you then build your user-facing data marts, which are often modeled as simple star schemas. This gives you the best of both worlds: a scalable, auditable core and fast, easy-to-query models for your BI developers and analysts.
Good Fit For:
Data Vault is a powerful but complex choice. It’s generally overkill for small teams or simple projects. You should consider it for:
- Large enterprises where full auditability of data is a strict legal or business requirement.
- Environments with many disparate source systems that need to be integrated flexibly. Adding a new source system is easier in Data Vault, as you can just add new satellites without redesigning the core model.
- Highly technical data teams that can manage the complexity and the multi-layered architecture (Raw -> Data Vault -> Data Marts).
Implementation: From DDL to Queries
To make this tangible, let’s write the CREATE TABLE statements for our university example and then see how we would load and query the data.
The DDL: Creating the Data Vault Structures
The following SQL creates the Hubs, Links, and Satellites. Note the common fields:
_hk: A Hash Key, typically a hash of the business key, serving as the primary key._lk: A Link Hash Key, a hash of the connected Hub keys.load_dts: The timestamp when the record was loaded, crucial for history.rec_src: The source system the record came from, crucial for auditability.
-- Hubs: The business entities
CREATE TABLE h_student (
student_hk BINARY(16) NOT NULL PRIMARY KEY, -- Hashed business key
student_id VARCHAR NOT NULL, -- The natural key from the source system
load_dts TIMESTAMP NOT NULL,
rec_src VARCHAR NOT NULL
);
CREATE TABLE h_course (
course_hk BINARY(16) NOT NULL PRIMARY KEY,
course_code VARCHAR NOT NULL,
load_dts TIMESTAMP NOT NULL,
rec_src VARCHAR NOT NULL
);
-- Link: The relationship between entities
CREATE TABLE l_enrollment (
enrollment_lk BINARY(16) NOT NULL PRIMARY KEY, -- Hashed combination of the two hub keys
student_hk BINARY(16) NOT NULL, -- Foreign key to h_student
course_hk BINARY(16) NOT NULL, -- Foreign key to h_course
load_dts TIMESTAMP NOT NULL,
rec_src VARCHAR NOT NULL,
FOREIGN KEY (student_hk) REFERENCES h_student(student_hk),
FOREIGN KEY (course_hk) REFERENCES h_course(course_hk)
);
-- Satellites: The descriptive, historical attributes
-- A satellite for descriptive student data
CREATE TABLE sat_student_details (
student_hk BINARY(16) NOT NULL, -- The parent hub key
load_dts TIMESTAMP NOT NULL, -- Part of the composite primary key
first_name VARCHAR,
last_name VARCHAR,
major VARCHAR,
rec_src VARCHAR NOT NULL,
PRIMARY KEY (student_hk, load_dts), -- This allows multiple versions for the same student
FOREIGN KEY (student_hk) REFERENCES h_student(student_hk)
);
-- A satellite for the grade, attached to the enrollment link
CREATE TABLE sat_enrollment_grade (
enrollment_lk BINARY(16) NOT NULL,
load_dts TIMESTAMP NOT NULL,
final_grade VARCHAR(2),
rec_src VARCHAR NOT NULL,
PRIMARY KEY (enrollment_lk, load_dts),
FOREIGN KEY (enrollment_lk) REFERENCES l_enrollment(enrollment_lk)
);
The Loading Process: An Insert-Only World
Imagine a student, Jane Doe, changes her major from ‘History’ to ‘Economics’.
- Traditional Model: You would run
UPDATE students SET major = 'Economics' WHERE student_id = 'S123';. The old value is gone forever. - Data Vault Model: You do not update. Instead, you run
INSERT INTO sat_student_details (...) VALUES (...)with the new major and the current timestamp. Both the ‘History’ record and the ‘Economics’ record now exist in the satellite, each with a differentload_dts.
Querying the Data Vault
You almost never give business users direct access to the Data Vault tables. They are too complex. Instead, you use the Data Vault as a stable foundation to build user-friendly data marts (often in a Star Schema).
Here are two common query patterns.
Query Pattern 1: Reconstructing a “Point-in-Time” View
This shows the power of auditability. Let’s find out what a student’s major was on January 1st, 2024.
-- Find the most recent student record *as of* a specific date
SELECT
s.student_id,
sat.first_name,
sat.last_name,
sat.major
FROM h_student AS s
JOIN sat_student_details AS sat
ON s.student_hk = sat.student_hk
WHERE s.student_id = 'S123'
AND sat.load_dts <= '2024-01-01 00:00:00' -- Only consider records loaded before our target date
QUALIFY ROW_NUMBER() OVER (PARTITION BY s.student_hk ORDER BY sat.load_dts DESC) = 1;
-- The QUALIFY clause is a common pattern in modern data warehouses (like Snowflake)
-- to pick the single most recent record for each student from the history.
This query looks at all historical records in the satellite for student ‘S123’ that existed before our target date and picks the newest one, giving you a perfect snapshot of the past.
Query Pattern 2: Building a Data Mart for Analytics
This is the most common use case. You join the hubs, links, and satellites to create a wide, denormalized table that can be used by analysts (this could be a fact table in a star schema or an OBT).
-- This query joins all the pieces to create a user-friendly view of enrollments
CREATE OR REPLACE VIEW vw_enrollment_details AS
WITH latest_student_details AS (
-- First, find the most recent version of every student's details
SELECT *
FROM sat_student_details
QUALIFY ROW_NUMBER() OVER (PARTITION BY student_hk ORDER BY load_dts DESC) = 1
),
latest_grades AS (
-- Then, find the most recent grade for each enrollment
SELECT *
FROM sat_enrollment_grade
QUALIFY ROW_NUMBER() OVER (PARTITION BY enrollment_lk ORDER BY load_dts DESC) = 1
)
SELECT
-- Keys from hubs and links
l.enrollment_lk,
s.student_id,
c.course_code,
-- Current descriptive attributes from student satellite
sd.first_name,
sd.last_name,
sd.major,
-- Current grade from enrollment satellite
g.final_grade,
-- Timestamps for audit
l.load_dts AS enrollment_date
FROM l_enrollment AS l
JOIN h_student AS s ON l.student_hk = s.student_hk
JOIN h_course AS c ON l.course_hk = c.course_hk
LEFT JOIN latest_student_details AS sd ON s.student_hk = sd.student_hk
LEFT JOIN latest_grades AS g ON l.enrollment_lk = g.enrollment_lk;
Now, your BI developers and analysts can query the simple vw_enrollment_details view without ever needing to know about the complex Hub, Link, and Satellite structure underneath. This gives you the best of both worlds: a perfectly auditable and scalable core, with a simple and fast layer for analytics.
Part VI. The Hierarchical Model: Organizing Data in Trees
How would you model an organization chart, a file system, or a product category structure? While you could use a relational model, these scenarios have a natural parent-child relationship that is perfectly suited for a hierarchical model.
This model organizes data into a tree-like structure. The rules are simple but strict:
- Each record, or “node,” can be a parent to one or more other nodes.
- Each “child” node has exactly one parent.
This one-parent rule is the defining characteristic of a hierarchy. A child cannot belong to two branches of the tree at the same time.
A Classic Example: The Org Chart
An employee reporting structure is a perfect real-world hierarchy. A CEO is at the top. VPs report to the CEO. Directors report to the VPs, and so on.
Visually, it looks like this:
CEO (Level 1)
├── VP of Engineering (Level 2)
│ ├── Manager A (Level 3)
│ │ ├── Engineer 1
│ │ └── Engineer 2
│ └── Manager B (Level 3)
└── VP of Sales (Level 2)
└── Sales Director (Level 3)
How is it Implemented?
While it looks like a tree, hierarchical data is often stored in two common ways:
-
In a Relational Table: Using a clever trick called a self-referencing foreign key. You create a single
employeestable where one column,manager_id, points back to theidcolumn of another employee in the same table.Table employees { id integer [pk] name varchar title varchar manager_id integer [ref: > employees.id] // Points to another employee }The CEO would be the only employee with a
NULLmanager_id. -
In a Document Format (like JSON): This is where the hierarchical model feels most natural. Data is stored as nested objects, directly mirroring the tree structure. This is extremely common in API responses and NoSQL databases.
{ "name": "VP of Engineering", "title": "VP", "reports": [ { "name": "Manager A", "title": "Manager", "reports": [...] }, { "name": "Manager B", "title": "Manager", "reports": [] } ] }
A Note on Object-Oriented Modeling: You may also hear the term “object-oriented modeling.” This is a paradigm from software engineering where data and the functions that operate on that data are bundled together into “objects.” While dedicated object-oriented databases are rare in analytics, the spirit of this approach lives on in document formats like JSON. A JSON document acts like a data object, encapsulating all the information about a single entity (like an employee and all their direct reports) in one place. For the data professional, thinking in terms of these document/object structures is most relevant when working with data from APIs or NoSQL sources.
Good Fit For:
The hierarchical model is highly efficient for its specific niche. Choose it for:
- Organizational charts and employee reporting structures.
- Product categories with nested sub-categories (e.g., Electronics > Computers > Laptops).
- File systems or folder structures.
- Geographic data that nests cleanly (e.g., Country > State > City).
- Commenting systems where replies are nested under parent comments.
Limitations
The model’s biggest strength—its rigid structure—is also its biggest weakness. It cannot represent many-to-many relationships. For example, what if “Engineer 1” also has a dotted-line report to a Project Manager in a different department? The hierarchical model cannot handle this. For those more complex, interconnected scenarios, we need a more flexible approach: the network or graph model.
Implementation and Querying in SQL
While a JSON structure is a natural fit, it’s very common to implement and query hierarchical data in a standard SQL database using the self-referencing key method. Here’s how it works in practice.
The DDL and Sample Data
First, we create the employees table. The manager_id column is a foreign key that points back to the id column in the very same table. It must be NULL-able to accommodate the person at the top of the hierarchy (the CEO).
CREATE TABLE employees (
id INTEGER PRIMARY KEY,
name VARCHAR(100) NOT NULL,
title VARCHAR(100) NOT NULL,
manager_id INTEGER, -- This will be NULL for the CEO
-- The self-referencing foreign key constraint
FOREIGN KEY (manager_id) REFERENCES employees(id)
);
-- Now, let's populate the table according to our org chart
INSERT INTO employees (id, name, title, manager_id) VALUES
(1, 'Alice', 'CEO', NULL),
(2, 'Bob', 'VP of Engineering', 1),
(3, 'Charlie', 'VP of Sales', 1),
(4, 'David', 'Engineering Manager', 2),
(5, 'Eve', 'Software Engineer', 4),
(6, 'Frank', 'Sales Director', 3);
The Query: Traversing the Tree
The main challenge with this structure is answering questions like, “Show me everyone who reports up to the VP of Engineering, directly or indirectly.” A simple JOIN can only go one level deep.
To traverse the entire tree, we need a special tool: a Recursive Common Table Expression (CTE). This is a standard SQL feature designed for exactly this kind of problem.
The query looks complex, but it has two simple parts:
- The Anchor: This is our starting point (e.g., the VP of Engineering, Bob).
- The Recursive Part: This part repeatedly finds the employees who report to the people found in the previous step, until there are no more levels to traverse.
-- Find the entire reporting chain for the VP of Engineering (id = 2)
WITH RECURSIVE employee_hierarchy AS (
-- 1. Anchor Member: Select the starting employee (our root)
SELECT
id,
name,
title,
manager_id,
1 AS level -- 'level' tracks how deep we are in the hierarchy
FROM employees
WHERE id = 2 -- Starting with Bob, the VP of Engineering
UNION ALL
-- 2. Recursive Member: Join employees to the hierarchy itself
SELECT
e.id,
e.name,
e.title,
e.manager_id,
eh.level + 1 -- Increment the level for each step down
FROM employees AS e
JOIN employee_hierarchy AS eh ON e.manager_id = eh.id -- This is the recursive join
)
-- Final SELECT to display the results
SELECT
level,
name,
title
FROM employee_hierarchy;
Result:
This query starts with Bob and finds his direct report (David), then finds David’s direct report (Eve), and stops. It returns a clean list of everyone in that branch of the organizational tree.
| level | name | title |
|---|---|---|
| 1 | Bob | VP of Engineering |
| 2 | David | Engineering Manager |
| 3 | Eve | Software Engineer |
This powerful pattern is the standard way to handle tree-like structures in SQL and is essential for querying hierarchical data effectively.
Part VII. The Graph Model: When Everything is Connected
In our last section, we saw the rigid structure of the hierarchical model: every child has exactly one parent. But what happens when relationships are more complex? What if an employee reports to two managers? What if a movie belongs to both “Comedy” and “Action” genres?
For these messy, real-world scenarios where relationships are just as important as the data itself, we turn to the graph model (also commonly known as a network model).
A graph model sheds the parent-child constraint and focuses on two simple components:
- Nodes (or Vertices): These are the entities or “things” in our domain. In a social network, nodes could be a
Person, aCompany, or aUniversity. - Edges (or Relationships): These are the connections that link the nodes. Unlike other models, edges are first-class citizens. They have a type and direction, describing how two nodes are related (e.g., a
PersonWORKS_AT aCompany, or IS_FRIENDS_WITH anotherPerson).
A Real-World Example: Social Networks
A social network like LinkedIn is the classic use case for a graph model. A relational database would struggle to answer “find me friends of my friends who work at Google” without incredibly complex and slow multi-table joins. In a graph, this is a natural and fast query.
Imagine this simple network:
(You) --[IS_FRIENDS_WITH]--> (Sarah) --[IS_FRIENDS_WITH]--> (David)
| |
+-----[WORKS_AT]-----> (Company A) (David) --[WORKS_AT]--> (Google)
In a graph database, you can start at the “(You)” node and “traverse” the edges to find connections. The query “friends of friends who work at Google” becomes:
- Find my friends (Sarah).
- Find their friends (David).
- Filter those people for ones who have a
WORKS_ATrelationship with the “Google” node.
How is it Implemented?
Graph models require specialized graph databases designed to store and query these relationships efficiently. Popular examples include Neo4j, Amazon Neptune, and TigerGraph. These databases use query languages like Cypher or Gremlin that are built for expressing traversal queries.
Good Fit For:
The graph model excels when the relationships between data points are the key to unlocking insights.
- Social Networks: Finding connections, suggesting friends, and analyzing influence.
- Recommendation Engines: “Customers who bought this product also bought…” or “Since you watched this movie, you might like that one because they share the same actors and director.”
- Fraud Detection: Identifying complex fraud rings by linking people who share addresses, phone numbers, or credit cards in non-obvious ways.
- Knowledge Graphs: Powering systems like Google’s Knowledge Panel or a corporate “expert finder” by linking people, skills, projects, and documents.
- Supply Chain & Logistics: Modeling complex networks to find optimal routes and identify single points of failure.
While incredibly powerful, graph models are more complex to set up and manage than traditional models, often requiring specialized skills and infrastructure. They are the sculptor’s choice for creating intricate, interconnected webs where every strand matters.
Implementation and Querying in a Graph Database
To work with graph models, you use a specialized graph database and a query language built for traversing relationships. The most popular language is Cypher, used by the Neo4j database. Cypher uses intuitive ASCII-art-like syntax to represent patterns in the graph.
- Nodes are represented with parentheses:
(node_name) - Relationships are represented with square brackets and arrows:
-[RELATIONSHIP_TYPE]->
Let’s build and query the social network example.
The “DDL”: Creating the Graph Data
In graph databases, you typically don’t have a rigid CREATE TABLE DDL. You create the data and its structure at the same time using CREATE statements that define nodes and the edges between them.
// Create the nodes (the entities)
CREATE (you:Person {name: 'You'})
CREATE (sarah:Person {name: 'Sarah'})
CREATE (david:Person {name: 'David'})
CREATE (compA:Company {name: 'Company A'})
CREATE (google:Company {name: 'Google'})
// Create the edges (the relationships)
// Note: We match the existing nodes and then create the relationship
MATCH (p1:Person {name: 'You'}), (p2:Person {name: 'Sarah'})
CREATE (p1)-[:IS_FRIENDS_WITH]->(p2)
MATCH (p1:Person {name: 'Sarah'}), (p2:Person {name: 'David'})
CREATE (p1)-[:IS_FRIENDS_WITH]->(p2)
MATCH (p:Person {name: 'You'}), (c:Company {name: 'Company A'})
CREATE (p)-[:WORKS_AT]->(c)
MATCH (p:Person {name: 'David'}), (c:Company {name: 'Google'})
CREATE (p)-[:WORKS_AT]->(c)
This code creates the exact graph structure we visualized earlier.
The Queries: Traversing the Network
Now we can ask the kinds of complex questions that are difficult for a relational database but natural for a graph.
Query 1: Find Friends of Friends
This is the classic graph query. The business question is: “Find me friends of my friends who work at Google.”
The Cypher query reads almost like a sentence describing the pattern you’re looking for.
// Find a path from 'You' to a 'friend' to a 'friend-of-a-friend' (fof)
// Then, check if that 'fof' works at Google.
MATCH (you:Person {name: 'You'})-[:IS_FRIENDS_WITH]->(friend:Person)-[:IS_FRIENDS_WITH]->(fof:Person)
WHERE
// Ensure we don't just recommend ourselves or people we're already friends with
NOT (you)-[:IS_FRIENDS_WITH]->(fof) AND you <> fof
// Now, match the pattern that this friend-of-a-friend works at Google
MATCH (fof)-[:WORKS_AT]->(company:Company {name: 'Google'})
// Return the name of the person we found
RETURN fof.name
Result:
This query effortlessly traverses the graph two “hops” away, filters the results, and finds the connection.
| fof.name |
|---|
| “David” |
Query 2: Recommendation Engine
Let’s ask a different question: “Who should I connect with at Google to get a job referral?” This translates to “Find the shortest path from me to anyone who works at Google.”
// Find the shortest path between 'You' and any employee at 'Google'
MATCH
path = shortestPath(
(you:Person {name: 'You'})-[*..5]-(employee_at_google:Person)
)
WHERE
(employee_at_google)-[:WORKS_AT]->(:Company {name: 'Google'})
RETURN path
shortestPath(...)is a powerful built-in function that finds the most direct route.[*..5]tells the database to look for any type of relationship up to 5 hops away.
This query would return the path: (You) -> (Sarah) -> (David), showing you that Sarah is your connection to David, who works at Google. This kind of pathfinding is incredibly complex in SQL but is a core strength of the graph model, making it ideal for recommendation engines and network analysis.
Conclusion: The Practice of Data Modeling
We’ve explored the journey of data modeling, from the initial process of understanding the business to the practical application of different patterns like the relational model, star schema, and graph. But knowing the patterns is only half the battle. To truly master this craft, it’s essential to remember that modeling is a dynamic and thoughtful practice. The goal is not to find a single, perfect answer, but to build a useful and evolving asset for your organization.
First, understand that data modeling is a conversation, not a declaration. Be prepared for an iterative process. It is completely normal to have multiple rounds of interviews with business stakeholders and downstream users before the design feels right. Your first draft will almost certainly not be your last. This back-and-forth is not a sign of failure; it is the core of the work, ensuring that what you build accurately reflects the business’s needs and is genuinely useful for those who will query it.
Second, recognize that there is no “one true model” that fits all use cases, even within the same company. Different business problems require different solutions. For example, a university might use a Data Vault model for its student records, where the primary need is strict auditability and historical tracking for compliance. At the same time, it could use a Dimensional Model (Star Schema) for its on-campus merchandise shop, where the goal is fast, flexible sales reporting for business analysts. The skilled data professional knows how to choose the right tool for the right job.
One of the most common decisions is choosing the grain, or the level of detail, for your model. For instance, in an e-commerce dataset, a model at the “order grain” (one row per customer order) can tell you total sales, but it can’t tell you which specific products are most popular. A model at the “order-line grain” (one row per product within an order) provides that deeper insight. A golden rule is to build your core models at the most detailed level possible, as you can always summarize detailed data, but you can never recover detail from a summary.
Finally, every modeling choice involves critical trade-offs that must be made with intention and then documented clearly. These decisions, and the reasons behind them, should be captured in your documentation (ERD, DDL code in DBT, DBT docs) so that the model remains understandable, maintainable, and valuable for everyone in the organization.
Appendix A: The Two Philosophies of Data Warehousing (Inmon vs. Kimball)
Now that we’ve explored the different data modeling patterns, let’s talk about the two dominant philosophies that guide how enterprise data warehouses are built and how they relate to the models in this article. These aren’t new modeling techniques, but rather competing architectural strategies: the “top-down” approach by Bill Inmon and the “bottom-up” approach by Ralph Kimball.
1. The Inmon Approach: The Corporate Information Factory (Top-Down)
-
Core Idea: First, build a centralized, highly normalized Enterprise Data Warehouse (EDW). This EDW serves as the single, integrated, and non-volatile source of truth for the entire company.
-
Model Used: The central EDW is built using a Relational Model normalized to the 3rd Normal Form (3NF), similar to the structure described in Part II. This prioritizes data integrity and eliminates redundancy at the core.
-
Data Flow:
Source Systems→ (ETL) → Central EDW (3NF Relational Model) → (ETL) →Departmental Data Marts (Star Schemas) -
Analogy: You build the main city library first (the EDW). It’s comprehensive, perfectly organized, and serves as the ultimate reference. Then, from that central library, you create smaller, specialized satellite libraries for different neighborhoods (the data marts) that are easier for the public to use.
-
Connection to This Article: Inmon’s philosophy uses the Relational Model (Part II) for its core warehouse and then builds Star Schemas (Part III) as the final layer for end-users. It treats the Data Vault (Part V) model as a potential evolution of the EDW core, valued for its auditability.
2. The Kimball Approach: The Dimensional Bus (Bottom-Up)
-
Core Idea: Instead of building a massive central repository first, you deliver value quickly by building individual data marts for specific business processes (e.g., sales, marketing, inventory). These marts are designed from the start to be integrated.
-
Model Used: The primary model is the Dimensional Model (Star Schema) from the beginning. Integration is achieved by using “conformed dimensions”—shared, identical dimension tables (e.g.,
dim_customer,dim_product) across all data marts. -
Data Flow:
Source Systems→ (ETL) →Data Marts (Star Schemas) -
Analogy: You build the neighborhood libraries first (the data marts), making them immediately useful to their communities. You ensure they all use the same card catalog system and library card (conformed dimensions), so over time, they function as a single, cohesive city-wide system.
-
Connection to This Article: Kimball’s philosophy is a direct and forceful advocate for using the Star Schema (Part III) as the primary and foundational building block for the entire data warehouse.
Appendix B: A Practical Example with Modern Data Sources
In many real-world projects, you don’t start with a blank slate. You work with data from existing systems like Salesforce, Google Analytics, or an application database. This data arrives in a predefined format you don’t control.
Let’s use a common example: a raw opportunities table synced from Salesforce into your data warehouse.
The Raw Source Data
Imagine a single, wide table named raw_salesforce_opportunities that looks like this. It’s denormalized and contains information about the opportunity, the account, and the account owner all in one place.
raw_salesforce_opportunities
| opportunity_id | opportunity_name | amount | close_date | account_id | account_name | account_industry | owner_id | owner_name | owner_email |
|---|---|---|---|---|---|---|---|---|---|
| op_1 | Project X | 50000 | 2023-10-25 | acct_A | ABC Corp | Tech | user_Z | Jane Doe | jane@… |
| op_2 | Project Y | 75000 | 2023-11-15 | acct_B | XYZ Inc | Finance | user_W | John Smith | john@… |
Your job is to model this raw data. Here’s how each philosophy would approach it.
Applying the Kimball (Bottom-Up) Approach
You would transform this raw table directly into a Star Schema.
- Create a Fact Table:
fct_opportunitiescontaining the core metrics and foreign keys. - Create Dimension Tables:
dim_accountsanddim_usersto hold the descriptive attributes.
The transformation logic maps the raw columns to their new homes:
fct_opportunitiesgetsopportunity_id,amount,close_date,account_id,owner_id.dim_accountsgetsaccount_id,account_name,account_industry.dim_usersgetsowner_id,owner_name,owner_email.
The end result is a clean, query-optimized Star Schema, ready for analysis.
Applying the Inmon (Top-Down) Approach
This is a two-step process. You don’t build the star schema right away.
Step 1: Normalize the data into a 3NF Enterprise Data Warehouse (EDW).
You first break the raw table apart into multiple, normalized tables that eliminate data redundancy.
edw_opportunities: (opportunity_id,opportunity_name,amount,close_date,account_id,owner_id)edw_accounts: (account_id,account_name,account_industry)edw_users: (user_id,user_name,user_email)
Notice that if Jane Doe’s name changes, you only update it in one row in edw_users. This is the core of normalization.
Step 2: Build a Data Mart from the EDW.
After the normalized EDW is built and populated, you then run a second transformation process to build a user-facing Star Schema (a data mart) from those EDW tables. The result looks identical to the Kimball output, but it was sourced from the clean, normalized EDW layer, not directly from the raw data.
Appendix C: Advanced Dimensional Modeling Patterns
While the standard Star Schema is the workhorse of analytics, real-world business scenarios sometimes require more specialized patterns. This appendix explores two powerful techniques used within dimensional modeling to solve common but complex problems: Snapshot Fact Tables for analyzing states over time, and Bridge Tables for resolving many-to-many relationships.
1. Snapshot Fact Tables
The Problem It Solves
A standard transactional fact table (like fct_payment_completed in Part III) is excellent for recording events that happen at a specific moment. However, many business questions aren’t about events; they’re about states. For example:
- “What was our total inventory value at the end of every month last year?”
- “How many open support tickets did we have at the start of each week?”
- “What was the account balance for every customer on the last day of the quarter?”
These questions require you to know the status of something at regular, predictable intervals. This is where a snapshot fact table comes in.
What It Is
A Snapshot Fact Table records the state of an entity at a specific point in time, repeated at a regular interval (e.g., daily, weekly, monthly). Instead of recording a single transaction, it takes a “picture” of a business process on a schedule.
Key Characteristics:
- Grain: The grain always includes a time component. For a daily snapshot, the grain is “one row per entity per day.”
- Measures are Semi-Additive: The metrics in a snapshot table (like
quantity_on_handoraccount_balance) are typically “semi-additive.” This means you can sum them across some dimensions (e.g., you can sumquantity_on_handacross all products to get total inventory) but not across the time dimension (summing daily inventory levels doesn’t give you a meaningful business number). You typically use averages, or first/last values, across the time dimension.
Example: Daily Inventory Snapshot
Imagine you need to track the quantity of each product in each warehouse at the end of every day.
fct_daily_inventory_snapshot
| date_key | product_key | warehouse_key | quantity_on_hand | inventory_value |
|---|---|---|---|---|
| 20231025 | 101 | 1 | 100 | 1999.00 |
| 20231025 | 102 | 1 | 250 | 12375.00 |
| 20231026 | 101 | 1 | 95 | 1899.05 |
| 20231026 | 102 | 1 | 250 | 12375.00 |
| 20231027 | 101 | 1 | 145 | 2898.55 |
In this table:
- On Oct 26, 5 units of product 101 were sold, so the
quantity_on_handdropped to 95. - On Oct 27, a new shipment of 50 units of product 101 arrived, so the quantity increased to 145.
- Product 102 had no activity, so its snapshot record is carried forward with the same values.
2. Bridge Tables
The Problem It Solves
A core assumption of the simple Star Schema is that a fact has a single, one-to-many relationship with each of its dimensions. But what about many-to-many (M:N) relationships?
- A single sales transaction can have multiple salespeople who split the commission.
- A single bank account can have multiple owners.
- A patient in a hospital can be diagnosed with multiple conditions during a single visit.
You cannot put salesperson_id_1, salesperson_id_2 in your fact table. This violates modeling principles and is impossible to query effectively.
What It Is
A Bridge Table is a simple, intermediary linking table that sits between a fact table and a dimension table to resolve a many-to-many relationship.
The structure looks like this:
Fact Table—joins to—>Bridge Table—joins to—>Dimension Table
Example: Medical Diagnoses for a Hospital Visit
Let’s say we have a fact table of hospital visits (fct_admissions) and a dimension of medical diagnoses (dim_diagnoses). A single admission can have many diagnoses.
Step 1: Create a “Group Key” for the many-to-many relationship. First, we create the Bridge Table. For every unique combination of diagnoses for a given visit, we create a group and assign it a key.
bridge_diagnoses_group
| diagnosis_group_key | diagnosis_key |
|---|---|
| 1 | D-101 (Pneumonia) |
| 1 | D-250 (Hypertension) |
| 2 | D-101 (Pneumonia) |
| 3 | D-430 (Diabetes) |
| 3 | D-250 (Hypertension) |
Here, diagnosis_group_key = 1 represents the case where a patient has both Pneumonia and Hypertension.
Step 2: Add the Group Key to the Fact Table.
The fact table does not contain the diagnosis_key. Instead, it contains the diagnosis_group_key which links to the bridge.
fct_admissions
| admission_key | patient_key | admission_date_key | diagnosis_group_key | total_charges |
|---|---|---|---|---|
| A-001 | P-555 | 20231025 | 1 | 15000 |
| A-002 | P-666 | 20231026 | 2 | 8000 |
| A-003 | P-777 | 20231027 | 3 | 22000 |
Now, to find the total charges for all patients with Pneumonia (D-101), the query would join fct_admissions to bridge_diagnoses_group on diagnosis_group_key, and then filter where diagnosis_key = ‘D-101’. This would correctly include admissions A-001 and A-002.
Note on Weighting Factors: For cases like sales commissions, the bridge table often includes a “weighting factor” column (e.g., commission_split_percentage) to properly allocate facts like revenue across the multiple salespeople.
Appendix D: A Real-World Case Study - The GA4 BigQuery Export Schema
So far, we’ve discussed data models as distinct patterns. In the real world, especially with modern data sources, these patterns are often blended together. There is no better example of this than the event data exported from Google Analytics 4 (GA4) to BigQuery.
Let’s deconstruct the GA4 schema to see how it applies the concepts from this article.
The Structure: One Giant, Nested Table
When you set up the GA4 export, you don’t get a clean set of normalized tables. Instead, you get one massive, wide table for each day (e.g., events_date). The grain of this table is one row per event.
A single row in this table might look conceptually like this (simplified):
event_date: "20231026"
event_name: "page_view"
user_pseudo_id: "12345.67890"
device: {
category: "desktop",
operating_system: "Macintosh"
}
geo: {
country: "United States",
city: "New York"
}
traffic_source: {
name: "google",
medium: "cpc"
}
event_params: [
{key: "page_location", value: {string_value: "https://example.com/pricing"}},
{key: "ga_session_id", value: {int_value: 1698340000}}
]
Let’s analyze this structure through the lens of our data modeling patterns.
It’s a “One Big Table” (OBT) Model
As discussed in Part IV, the OBT model prioritizes query performance by denormalizing everything into a single table. The GA4 schema is a quintessential OBT.
- No Joins Needed: All the information about the event—the user, the device, the geography, the traffic source—is contained within that single row. To find out how many users from New York visited on a desktop, you don’t need to
JOINtodim_geoanddim_devicetables. You just query the singleevents_*table. - Massive Redundancy: The user’s country (“United States”) and device category (“desktop”) are repeated for every single event they trigger. This is a deliberate trade-off. Storage is cheaper than compute, and this redundancy makes analytical queries lightning fast on a columnar database like BigQuery.
It’s a “Hierarchical” Model
As we saw in Part V, hierarchical models are great for nested data. The GA4 schema uses this concept extensively, not with self-referencing keys, but with nested RECORD (also called STRUCT) and ARRAY types.
-
Nested
RECORDs: Fields likedevice,geo, andtraffic_sourceareRECORDtypes. They act like organized folders or JSON objects within the row. Instead of having flat, prefixed columns likedevice_categoryanddevice_operating_system, the data is neatly grouped. You access it with dot notation:SELECT device.category, geo.country FROM `my_project.my_dataset.events_*`; -
Repeated Nested Records (
ARRAYofRECORDs): The most powerful example is theevent_paramsfield. It is anARRAYofRECORDs. This is a hierarchical one-to-many relationship inside a single row. One event can have many parameters, and they are all stored together. To query this, you need to “flatten” the hierarchy using theUNNEST()function:-- Find the page location for all 'page_view' events SELECT event_name, params.value.string_value AS page_location FROM `my_project.my_dataset.events_*`, UNNEST(event_params) AS params -- This turns the nested array into flat rows WHERE event_name = 'page_view' AND params.key = 'page_location';
Conclusion: A Modern OLAP Model
The GA4 schema is a sophisticated OLAP (analytical) model, absolutely not an OLTP model. It is designed for one purpose: to analyze massive volumes of event data quickly.
- It’s an OBT to minimize
JOINs and maximize aggregation speed. - It’s Hierarchical to manage the complexity of its hundreds of potential fields in an organized way.
For a data team, this raw, nested OBT is often the starting point. The next step in the data modeling process is to transform this complex source into cleaner, more business-friendly models—often Star Schemas (Part III) or simpler, more targeted OBTs—that power BI dashboards and further analysis.
Appendix E: Matching the Model to the Database Technology
Choosing a data model is not just an abstract design exercise; it has direct implications for the technology you will use. Different databases are engineered to excel at the specific query patterns dictated by each model. Aligning your model with the right database is critical for performance, scalability, and cost-effectiveness.
Here’s a guide to which database categories best fit the models discussed in this article.
1. Relational Model (Normalized / 3NF)
- Primary Use Case: OLTP (Online Transaction Processing) systems, such as application backends, e-commerce stores, and financial transaction systems.
- Query Patterns: High volume of reads, writes, updates, and deletes on individual rows (
INSERT,UPDATE,DELETE). Queries are typically for a single entity or a few related ones (e.g., “get this user’s profile and their last 5 orders”). - Best Fit Database Category: Row-Store Transactional Databases.
- These databases store all the data for a single row together on disk. This makes it extremely fast to read, update, or delete an entire row, as it’s a single I/O operation.
- Example Technologies:
- PostgreSQL: A powerful, open-source object-relational database known for its robustness and feature set.
- MySQL: The world’s most popular open-source database, widely used for web applications.
- Microsoft SQL Server & Oracle Database: Leading commercial databases for enterprise applications.
2. Dimensional Model (Star Schema & OBT)
- Primary Use Case: OLAP (Online Analytical Processing), business intelligence, data warehousing, and large-scale reporting.
- Query Patterns: Aggregations (
SUM,COUNT,AVG) across millions or billions of rows. Queries scan a few columns from a very wide table but ignore the rest (e.g.,SUM(sales) GROUP BY product_category). - Best Fit Database Category: Columnar Analytical Databases / Data Warehouses.
- These databases store data by column, not by row. When you run
SUM(sales), the database only reads thesalescolumn from disk, dramatically reducing I/O and making aggregations incredibly fast. This structure also allows for very high data compression.
- These databases store data by column, not by row. When you run
- Example Technologies:
- Cloud Data Warehouses: Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse.
- Open-Source Analytical Engines: ClickHouse, Apache Druid.
- In-Process Analytical Database: DuckDB. This is a special and increasingly popular case. It runs inside your application (like a Python script) and provides extremely fast OLAP capabilities on local data (e.g., Parquet files or pandas DataFrames), making it perfect for local data science and smaller-scale analytics.
3. Hierarchical Model
This model has two common implementations, each with its own ideal database.
- A) Implemented with a Self-Referencing Key (in a Relational DB):
- Use Case: Org charts, product categories, or file systems stored in a traditional database.
- Best Fit Database Category: Row-Store Transactional Databases that support recursive queries.
- Example Technologies: PostgreSQL and SQL Server are particularly good at this, as their support for
WITH RECURSIVECTEs is highly optimized.
- B) Implemented with Nested Objects:
- Use Case: Storing flexible, self-contained data like API responses, user profiles with nested attributes, or content management systems.
- Best Fit Database Category: Document-Oriented NoSQL Databases.
- Example Technologies:
- MongoDB: Stores data in a flexible, JSON-like format called BSON, which naturally maps to hierarchical objects.
- Google Firestore / AWS DynamoDB: Managed NoSQL document databases that excel at handling nested data structures at scale.
4. Graph Model
- Primary Use Case: Network analysis, recommendation engines, fraud detection, and knowledge graphs.
- Query Patterns: Traversals, pathfinding, and analyzing the relationships between entities (e.g., “find friends of my friends who live in New York”).
- Best Fit Database Category: Native Graph Databases.
- These databases are engineered from the ground up to treat relationships (edges) as first-class citizens. The storage engine is optimized for “hopping” from one node to another, making traversal queries that would be painfully slow in a relational database almost instantaneous.
- Example Technologies:
- Neo4j: The most popular native graph database, which uses the Cypher query language.
- Amazon Neptune: A managed cloud graph database that supports multiple query languages (Gremlin, SPARQL).
- TigerGraph: A high-performance graph database designed for massive-scale analytics.
Summary Table
| Data Model | Primary Use Case | Database Category | Example Technologies |
|---|---|---|---|
| Relational (3NF) | OLTP / Application Backend | Row-Store Transactional | PostgreSQL, MySQL, SQL Server |
| Dimensional (Star/OBT) | OLAP / Data Warehouse | Columnar Analytical | Snowflake, BigQuery, Redshift, DuckDB |
| Hierarchical (Nested) | Document / Flexible Schema | Document-Oriented NoSQL | MongoDB, Firestore |
| Graph | Network / Relationship Analysis | Native Graph Database | Neo4j, Amazon Neptune, TigerGraph |